Zero-Shot Temporal Action Localization Through Textual Guidance
Benedetta Liberatori, Alessandro Conti, Lorenzo Vaquero, Paolo Rota, Yiming Wang, Elisa Ricci. Face and Gestures 2026.
Associate Professor @ CIMeC/DISI - University of Trento
Palazzo Fedrigotti - Room 216 - Rovereto
Polo Ferrari - Room 110 - Povo 2
I am Paolo Rota, associate professor at the University of Trento and ELLIS member, working in computer vision, machine learning, and multimodal AI. My research focuses on vision-language models and activity recognition, with applications in video analytics and industrial AI.
My research focuses on computer vision and machine learning, with a particular emphasis on video understanding and multimodal AI. I investigate methods that bridge vision and language, addressing challenges such as zero-shot action recognition, temporal action localization, and open-world recognition using large vision–language models. More broadly, I work on representation learning and domain adaptation to build systems capable of robust visual understanding in dynamic and real-world environments. I am also interested in evaluation protocols and benchmark design for video analytics, aiming to develop principled and reliable ways to assess multimodal AI systems.
Outside of academia, I co-founded Mountain Maps, a startup that uses AI to enhance outdoor navigation and help people explore mountain environments more safely and enjoyably.
I’m pleased to share that I will serve as Web Co-Chair for ACM MM 2026, which will be held in Rio de Janeiro in October. Please feel free to report anything on the website that does not appear or function as expected! :S
We are pleased to share that our work TerraScope will appear at CVPR 2026.
Current VLMs still struggle with fine-grained spatial perception, a key requirement for accurate reasoning in Earth Observation. TerraScope addresses this limitation through a pixel-grounded reasoning framework that interleaves segmentation masks with chain-of-thought reasoning, enabling more precise and interpretable geospatial analysis.
Congrats to Yan!!
It took almost 2 years to get the first round of reviews but eventually we got our paper accepted!
Conti, Alessandro, et al. "Vocabulary-free Image Classification and Semantic Segmentation." IEEE Transactions on Pattern Analysis and Machine Intelligence (2026).
Hi everyone, the CfP of MULA workshop is out. Take a look at the website for more info.
Deadline for full paper submissions is on March 9th AoE!!
Shiyao’s paper has been accepted to 3DV 2026!
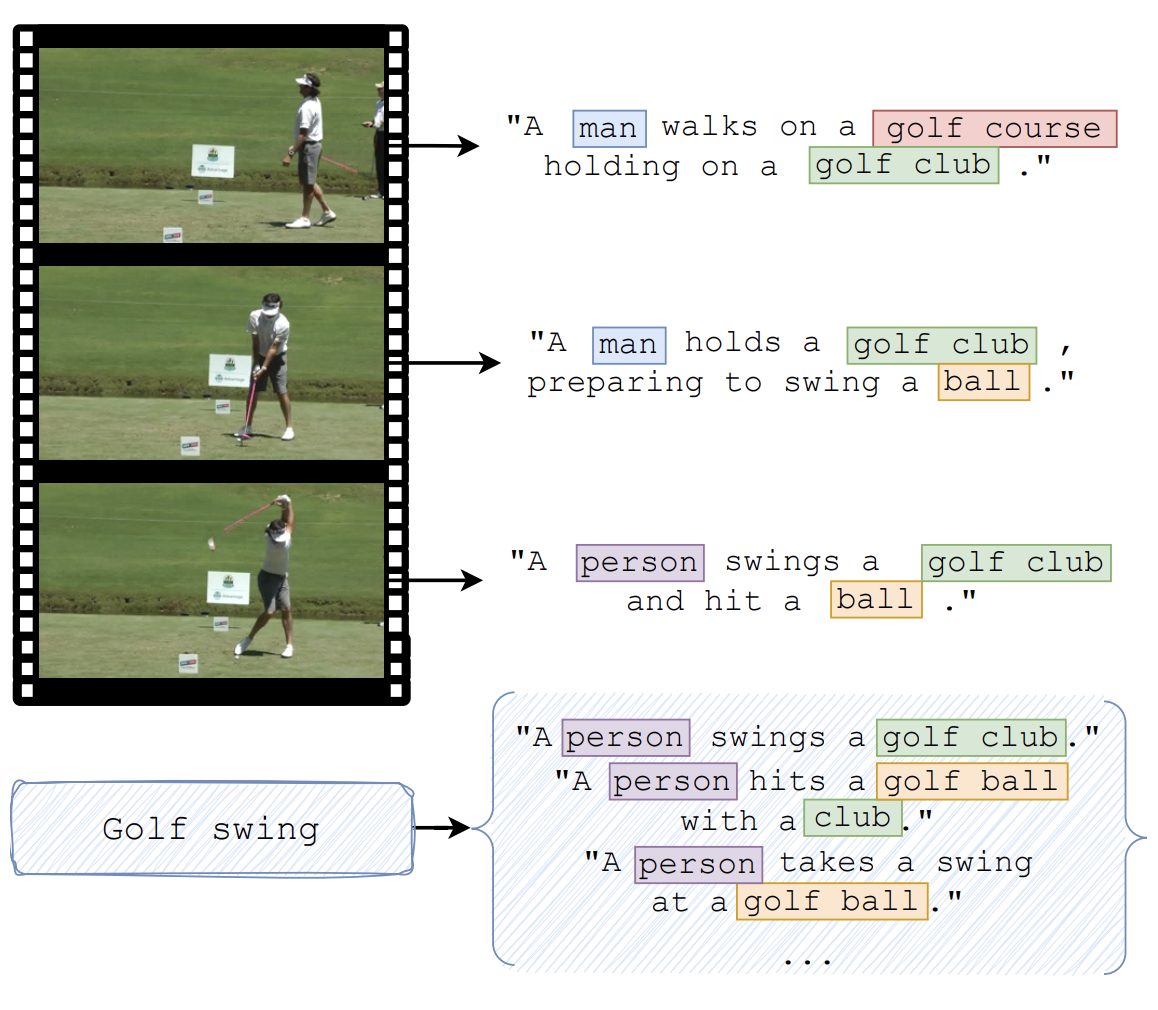
The work focuses on Motion Captioning, with the goal of developing a model that can describe not only what action is happening, but also when it occurs by accurately identifying its temporal boundaries, as the title: Dense Motion Captioning.
For more details, visit the project webpage: https://xusy2333.com/demo/